

Four common questions about the science behind Pera
13 September 2022
How can language provide insight in your personality and competencies?
Your language is as unique as a fingerprint and provides insight in your personality and key competencies. But what kind of language analysis techniques can be used to obtain these insights? The most common techniques in the computational linguistics field to infer personality and competencies from natural language are listed below:
-
Analyzing word categories
Pennebaker and King (1999) were the first to investigate correlations between frequencies of word categories and personality traits. They discovered simple relations that could predict personality traits above chance-level, for instance:- People who use more articles and more words of more than 6 letters score above average and are more open to new experiences.
- People who frequently use negative emotional words and the first-person singular tend to be more neurotic.
- People who use few negative emotion words and negations, are on average more conscientious.
-
Analyzing individual words
Schwartz et al. (2013) looked at the relations between individual words and personality traits. Given a large number of words in a language, such an analysis can only be conducted on a very large corpus (in their case 700 million words from 15.4 million Facebook messages). They discovered that the frequencies of individual words, phrases or topics can be used to infer personality from language, for example:- Extraverted people use words like “party” and “chilling” more frequently than introverts, whereas introverted people use words like “computer”, “internet” and “anime” more frequently than extraverts.
-
Analyzing writing style
Instead of analyzing on what someone writes, researchers such as Daelemans (2003) have focused on how someone writes. This method is known as computational stylometry and involves looking at stylistic features such as character sequences, punctuation, word sequences, parse trees, readability, vocabulary richness measures, or discourse features. The work- People who use more punctuation and have richer vocabulary, are more open to new experiences.
-
Deep learning
More recently, deep learning techniques have been introduced in the field of computational linguistics. Deep learning has resulted in very significant performance gains for almost any task in computational linguistics, including personality and competency inference. Because of these significant performance gain compared to traditional methods, Pera primarily relies on deep learning models to compute the outcomes of the digital interview.
References:
- Pennebaker, J. W., & King, L. A. (1999). Linguistic styles: language use as an individual difference. Journal of personality and social psychology, 77(6), 1296.
- Schwartz, H. A., Eichstaedt, J. C., Kern, M. L., Dziurzynski, L., Ramones, S. M., Agrawal, M., & Ungar, L. H. (2013). Personality, gender, and age in the language of social media: The open-vocabulary approach. PloS one, 8(9), e73791.
- Daelemans, W. (2013, March). Explanation in computational stylometry. In International Conference on Intelligent Text Processing and Computational Linguistics (pp. 451-462). Springer, Berlin, Heidelberg.
What are the steps to train an organization-specific predictive model?
In the figure below an overview is presented of the different steps in training a model for a specific organization. In the first step, the client selects the key traits and competencies required in the organization or for the specific job function and selects a representative sample of at least 50 employees. This sample should include top performers, average performers, and low performers. The employees in the sample are invited to respond to a small number of open-ended questions.
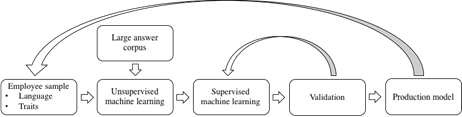 Overview of Pera methodology for organization-specific predictive models
Overview of Pera methodology for organization-specific predictive models Furthermore, managers, HR professionals, peers, and even customers then provide 360-degree performance feedback on these employees about key traits and competencies. To ensure a statistically valid and fair dataset, Pera developed an online 360-degree performance feedback module. In this online module, raters are asked to compare employees against each other, for example “who (of the two persons below) most exhibits the following competency?”. These comparative ratings provide much more granular insights into the competencies of employees than traditional ratings on an absolute 1-5 scale.
After the 360-degree performance feedback, as well as the language from the sample employees have been collected, an unsupervised machine learning algorithm pre-processes the answers to the open-ended questions and converts each of them to a dense N-dimensional vector. Next, the vector representations of the answers and the human scores for competencies and behaviours are used as inputs by a supervised machine learning algorithm to generate a predictive model.
Pera uses k-fold cross-validation to validate the model internally, but in the validation step the client also can validate the model on an additional sample of employees not previously seen by Pera. Data from the validation phase are used to update the model, and once this step is completed the model is production ready.
During the deployment of the model, candidates are invited to answer the same open-ended questions as answered by the sample of employees. Based on the predictions for each of the key traits and competencies, an overall digital interview score is computed that expresses the degree of fit for a specific role. The overall score as well as the individual scores for each trait or competency are reported as percentile scores. That means, the scores reflect how a candidate compares to a norm group of candidates in similar roles.
For a subset of custom models, hard performance data is available such as sales revenue numbers or other KPIs based on hard data. If available, Pera will use the hard performance data for two purposes, namely:
- To assign optimal weights to the traits and competencies estimated from a digital interview.
- To quantify the predictive power of the digital interview and estimate the expected business impact.
Model development does not stop after the initial model has been deployed. By periodically adding language data and trait scores of new hires to the employee sample, the predictive model gradually increases its accuracy over time.
Developing a custom predictive model sounds like a significant effort. Isn’t there an easier way to use the Pera digital interview?
Fortunately, there is.
In the beginning of Pera, any organization interested in the digital interview, would first need to provide Pera with 360-degree performance data and language data from their employees. Based on this data, Pera would train a model that predicts organization-specific competencies from a digital interview. These organization-specific models are referred to as custom models. See also the question below about “What are the steps to train an organization-specific predictive model?”.
After developing custom models for many companies, languages, jobs and industries, researchers at Pera realized two things:
- There is a significant overlap of relevant competencies across organizations and roles. Careful clustering of the competency descriptions across the many custom models resulted in 9 clusters of competencies that (1) significantly measure something different and (2) were frequently used across different organizations and roles.
- There exists overlap in the linguistic markers that drive these competency predictions across different custom models.
Based on these two insights, Pera trained predictive models for these 9 trait clusters that generalize relatively well over different organizations and job roles. Because of their generalizability, these models are referred to as generic models.
Nowadays, organizations, therefore, have two options to score the digital interview:
- A custom model that can compute organization-specific competencies but requires high-quality training data to be provided in advance.
- A generic model that is readily available to be used and can compute the scores of up to nine different generic competencies from a digital interview.
Do non-native speakers obtain lower scores on the digital interview?
The short answer is no. We simply do not look at language features that highly correlate with being a non-native speaker, such as grammar mistakes or typos.
In 2016, a custom predictive model was used to recruit young professionals for a leadership program about sustainability and impact creation. More than 1700 candidates from more than 100 different countries responded in English to four open-ended questions, and digital interview scores for each candidate were computed. Because the native language of candidates was not known, the official languages of the country of origin were used as an alternative means to determine native and non-native English speakers.
Statistical analysis showed that whether candidates originated from a non-native English-speaking country explained less than 1 per cent of the variance in the digital interview scores, which is practically insignificant.
If you would like to learn more or read about the many customer stories, please read our white paper.